Intuition
As the name implies, a two-pointer pattern refers to an algorithm that utilizes two pointers. But what is a pointer? It's a variable that represents an index or position within a data structure, like an array or linked list. Many algorithms just use a single pointer to attain or keep track of a single element:
![The image represents a visual depiction of data insertion or modification within a data structure, likely an array or list. A small, orange square containing the letter 'i' acts as an indicator or pointer, positioned above a sequence of numbers enclosed in square brackets: `[ ... 14 5 5 20 ... ]`. A downward-pointing orange arrow originates from the 'i' indicator and points directly to the number '5', suggesting that the 'i' represents a position or index within the data structure, and the arrow indicates the insertion or modification is occurring at that specific index. The ellipses (...) indicate that there are additional elements before and after the visible portion of the sequence. The overall diagram illustrates a simple data manipulation operation, focusing on the insertion or update of a value at a particular index within a larger dataset.](https://ik.imagekit.io/pgwvcyhjsd/bytebytego/coding-patterns/two-pointers--introduction-to-two-pointers/1777012648500_img-0.svg)
Introducing a second pointer opens a new world of possibilities. Most importantly, we can now make comparisons. With pointers at two different positions, we can compare the elements at those positions and make decisions based on the comparison:
![Image represents a visual depiction of a comparison step within a sorting algorithm, likely a comparison-based sort like bubble sort or insertion sort. The diagram shows a numerical array `nums` represented as `[... 14 5 5 20 ...]`, indicating a partial view of a larger array. Two index variables, `i` (in an orange box) and `j` (in a light-blue box), point to elements 14 and 5 respectively within the array. Arrows descend from `i` and `j` to highlight these selected elements. To the right, a dashed-line box describes a function call `compare(nums[i], nums[j])`, which implies a comparison operation between the values at indices `i` and `j` (14 and 5 in this instance). A right-pointing arrow from this box leads to the text 'make decision,' indicating that the result of the comparison (whether `nums[i]` > `nums[j]`, `nums[i]` < `nums[j]`, or `nums[i]` == `nums[j]`) will determine the next step in the sorting algorithm.](https://ik.imagekit.io/pgwvcyhjsd/bytebytego/coding-patterns/two-pointers--introduction-to-two-pointers/1777012648501_img-1.svg)
In many cases, such comparisons are made using two nested for-loops, which takes time, where n denotes the length of the data structure. In the code snippet below, i and j are two pointers used to compare every two elements of an array:
for i in range(n):
for j in range(i + 1, n):
compare(nums[i], nums[j])
Often, this approach does not take advantage of predictable dynamics that might exist in a data structure. An example of a data structure with predictable dynamics is a sorted array: when we move a pointer in a sorted array, we can predict whether the value being moved to is greater or smaller. For example, moving a pointer to the right in an ascending array guarantees we're moving to a value greater than or equal to the current one:
![Image represents a diagram illustrating a coding pattern or prediction within a sorted array. At the top, a small orange square containing the letter 'i' points downwards, indicating an index or iterator. Below, a sorted integer array `[1 2 3 4]` is shown, with a grey line underneath labeled 'sorted array'. A dashed-line box at the bottom contains a prediction statement written in a pseudo-code style: 'prediction: if nums[i] == 2, then nums[i + 1] ≥ 2'. This statement suggests that if the element at index 'i' in the `nums` array is equal to 2, then the element at the next index (i+1) must be greater than or equal to 2. The arrow from 'i' implies that 'i' is used to index into the array, likely as part of an algorithm or conditional check.](https://ik.imagekit.io/pgwvcyhjsd/bytebytego/coding-patterns/two-pointers--introduction-to-two-pointers/1777012648502_img-2.svg)
As you can see, data structures with predictable dynamics let us move pointers in a logical way. Taking advantage of this predictability can lead to improved time and space complexity, which we will illustrate with real interview problems in this chapter.
Two-pointer Strategies
Two-pointer algorithms usually take only time by eliminating the need for nested for-loops. There are three main strategies for using two pointers.
Inward traversal
This approach has pointers starting at opposite ends of the data structure and moving inward toward each other:
The pointers move toward the center, adjusting their positions based on comparisons, until a certain condition is met, or they meet/cross each other. This is ideal for problems where we need to compare elements from different ends of a data structure.
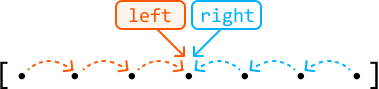
Unidirectional traversal
In this approach, both pointers start at the same end of the data structure (usually the beginning) and move in the same direction:
![The image represents a visual depiction of a two-pointer approach to traversing a data structure, likely an array or list. The structure is shown as a sequence of black dots enclosed within square brackets `[ ]`, representing individual elements. An orange rectangle labeled 'left' points a downward arrow to the leftmost element within a subset of the dots. Dashed orange lines with arrowheads connect this element to the next few elements to its right, indicating a traversal from left to right. Similarly, a light-blue rectangle labeled 'right' points a downward arrow to the rightmost element within a different subset of the dots. Dashed light-blue lines with arrowheads connect this element to the preceding few elements to its left, indicating a traversal from right to left. The two pointers, indicated by the orange and light-blue arrows, are moving towards the center of the data structure, suggesting a merging or comparison process commonly used in algorithms like merge sort or two-pointer techniques for finding pairs with a specific sum.](https://ik.imagekit.io/pgwvcyhjsd/bytebytego/coding-patterns/two-pointers--introduction-to-two-pointers/1777012651216_img-4.svg)
These pointers generally serve two different but supplementary purposes. A common application of this is when we want one pointer to find information (usually the right pointer) and another to keep track of information (usually the left pointer).
Staged traversal
In this approach, we traverse with one pointer, and when it lands on an element that meets a certain condition, we traverse with the second pointer:
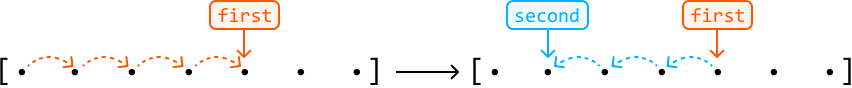
Similar to unidirectional traversal, both pointers serve different purposes. Here, the first pointer is used to search for something, and once found, a second pointer finds additional information concerning the value at the first pointer.
We discuss all of these techniques in detail throughout the problems in this chapter.
When To Use Two Pointers?
A two-pointer algorithm usually requires a linear data structure, such as an array or linked list. Otherwise, an indication that a problem can be solved using the two-pointer algorithm, is when the input follows a predictable dynamic, such as a sorted array.
Predictable dynamics can take many forms. Take, for instance, a palindromic string. Its symmetrical pattern allows us to logically move two pointers toward the center. As you work through the problems in this chapter, you'll learn to recognize these predictable dynamics more easily.
Another potential indicator that a problem can be solved using two pointers is if the problem asks for a pair of values or a result that can be generated from two values.
Real-world Example
Garbage collection algorithms: In memory compaction – which is a key part of garbage collection – the goal is to free up contiguous memory space by eliminating gaps left by deallocated (aka dead) objects. A two-pointer technique helps achieve this efficiently: a 'scan' pointer traverses the heap to identify live objects, while a 'free' pointer keeps track of the next available space to where live objects should be relocated. As the 'scan' pointer moves, it skips over dead objects and shifts live objects to the position indicated by the 'free' pointer, compacting the memory by grouping all live objects together and freeing up continuous blocks of memory.
Chapter Outline
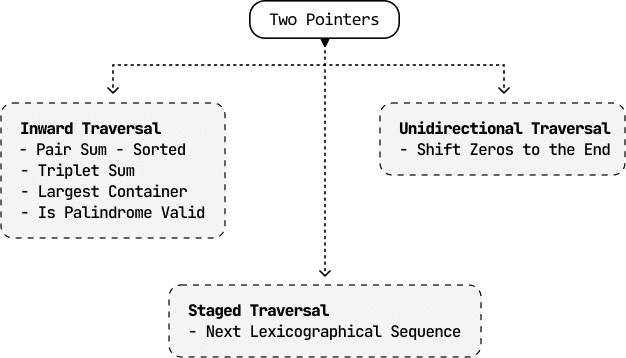
The two-pointer pattern is very versatile and, consequently, quite broad. As such, we want to cover more specialized variants of this algorithm in separate chapters, such as Fast and Slow Pointers and Sliding Windows.